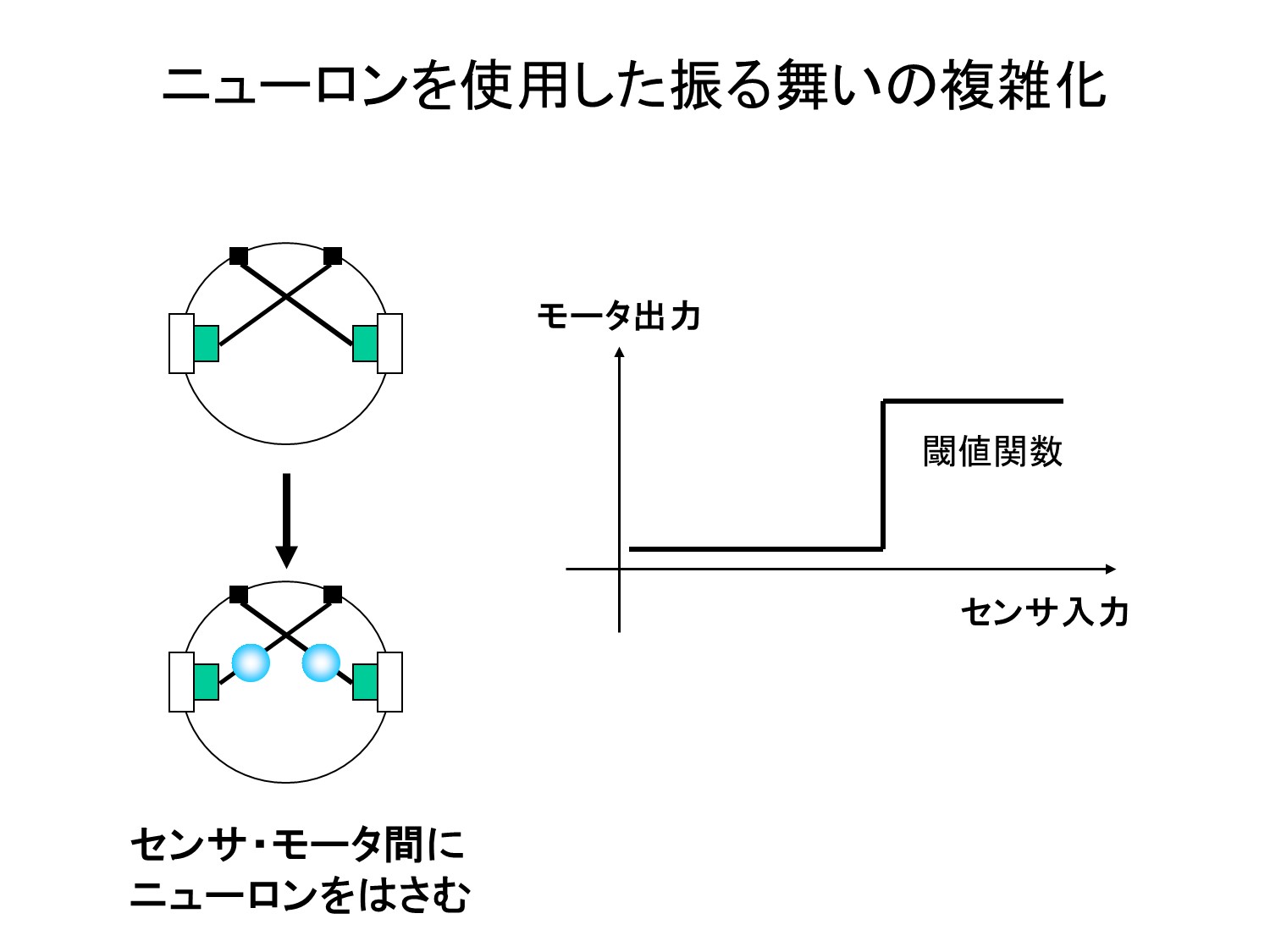
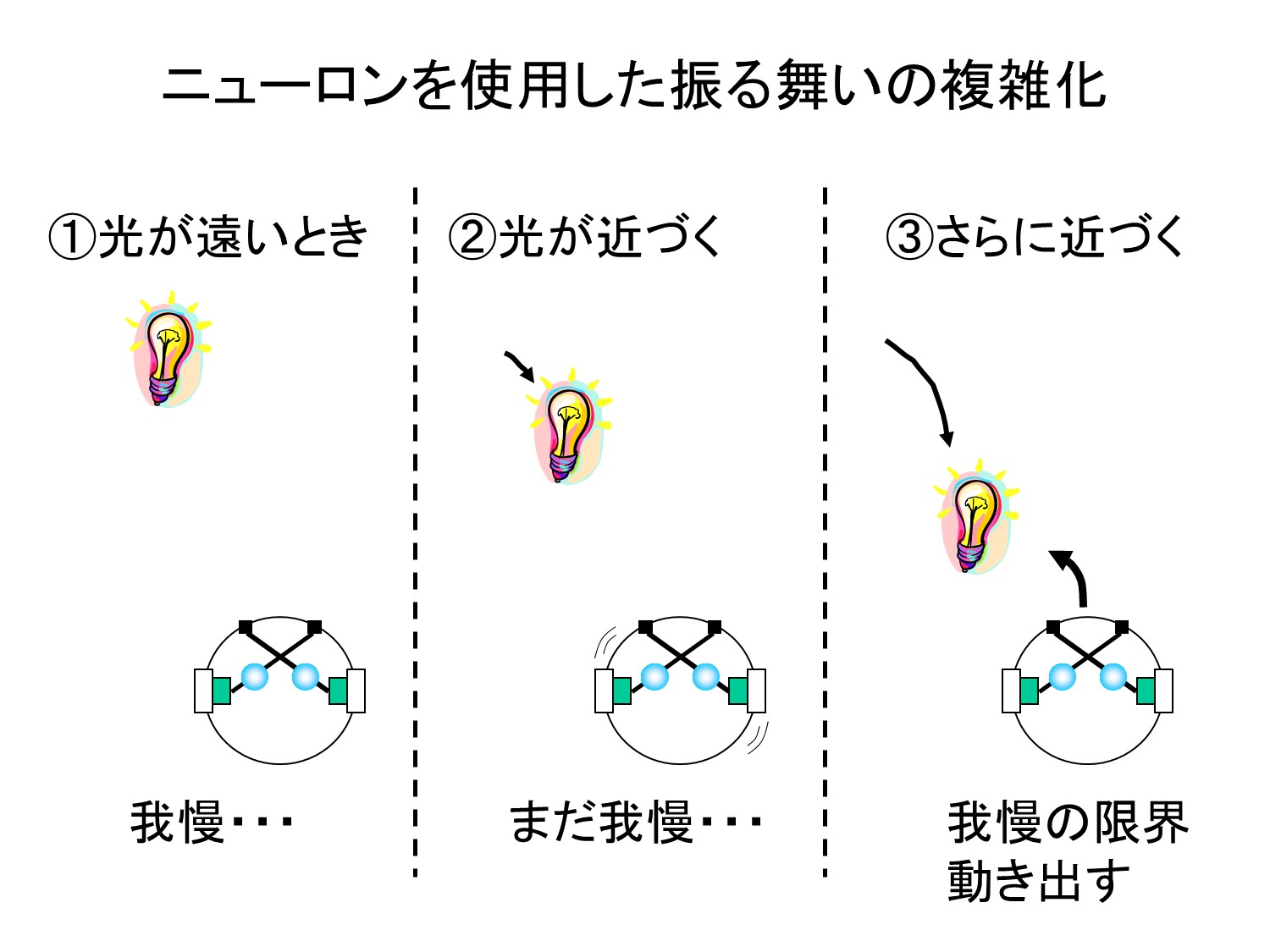
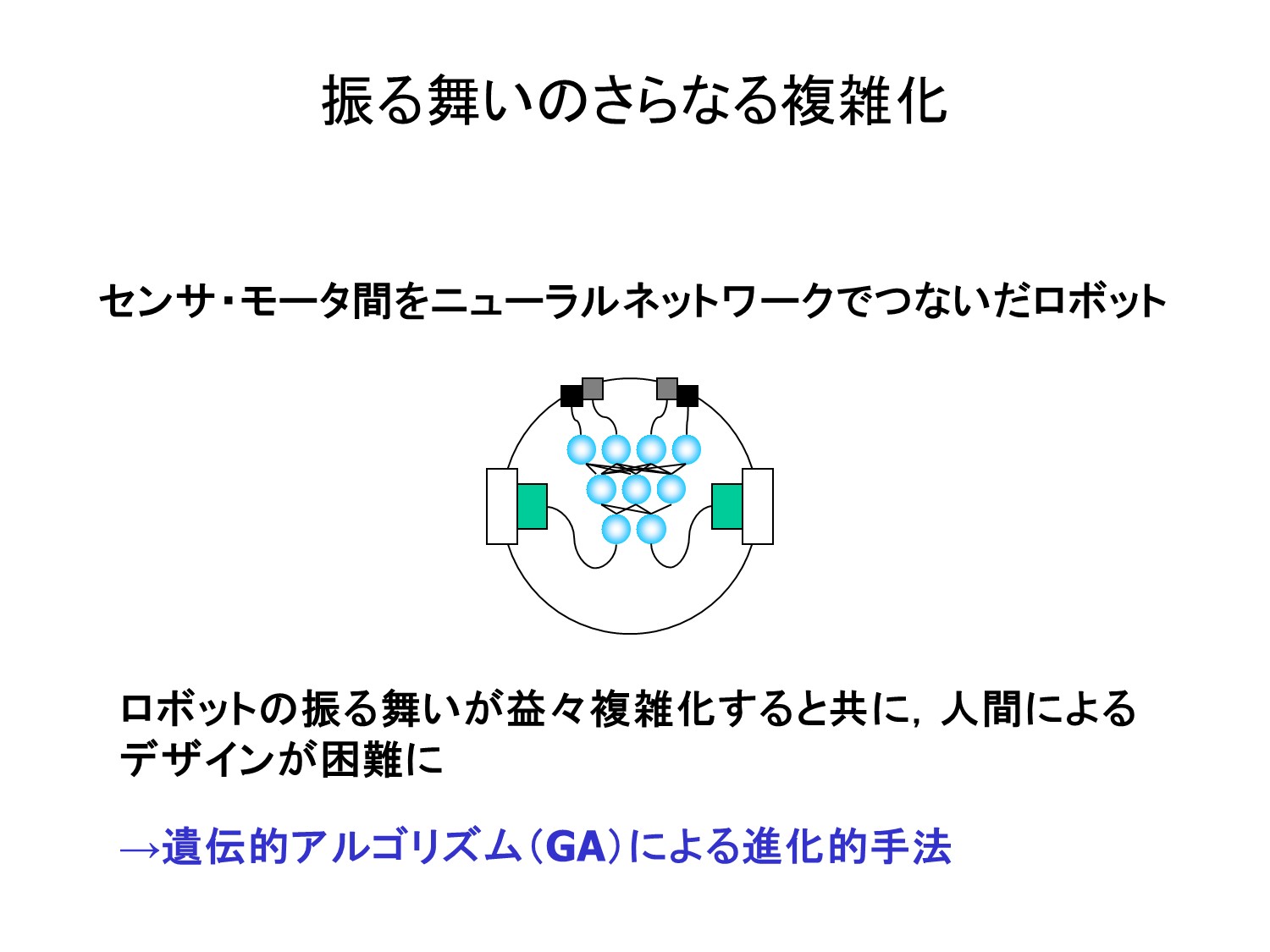
こんにちは、トロボです。
今年の桜は早かったですね。東京ロボティクスのオフィスがある江戸川橋から早稲田にかけての神田川沿いは桜の名所になっていて、通勤途中に遠回りしてしまうくらい見ごたえがありました。
さて、今回は触覚センサアレイを用いた物体の変形・滑り検知のデモをご紹介します。まずは以下の動画をご覧ください。
グリッパの指先に搭載した触覚センサから得られる物体との接触情報を処理することで、柔らかい物体は潰さずに、滑りやすい物体は落とさずにピッキングできていることが分かると思います。
今後の自律ロボットのアプリケーションを考えると、身近なところではスーパーやコンビニ、食品・化粧品・医薬品といった三品産業の工場、EC向けの倉庫といった場所で、多種多様な物品を扱わなければなりません。ロボットにはそれぞれの物体を潰したり落としたりせずに、巧みにピッキングする能力が求められます。そのためには、触覚センサから得られるデータから物体の変形や滑りを捉えることによって、どの程度の力加減で掴めばよいのかを判断する機能が必要になります。
カメラ等の画像情報を使って変形や滑りを検知している研究[1]もありますが、目に見える範囲で商品を変形させない、滑らせない、という検知手法では、商品の美粧性を損ねるリスクがあります。力覚センサを使うことも可能ですが、物体とグリッパの接触面に分布して表れる変形や滑りといった現象に対して点で計測することになるので、きめ細かい変形・滑り検知が難しいと言えます。加えて、値段やサイズの問題もあります。そこで今回ご紹介する技術では、触覚センサのみを用いて目に見えない微細な変化を捉えることで、物体の変形や滑りを素早く検知するアプローチを採用しています。
変形は物体を掴むときに、滑りは持ち上げる時に生じます。言い換えると、物体とグリッパの爪が接触する垂直方向と接線方向にそれぞれの現象が起こりますので、各方向の接触情報を取得できるセンサが必要となります。今回は分布型3軸触覚センサ「uSkin」と呼ばれるものを使います。これは、3軸方向を計測できる触覚点が格子状に分布した形になっており、上述したような変形や滑りといった現象を各方向で捉えやすいものとなっています。下図に示すように、グリッパの指先に貼り付けるだけで済むなど、取り付けも容易です。
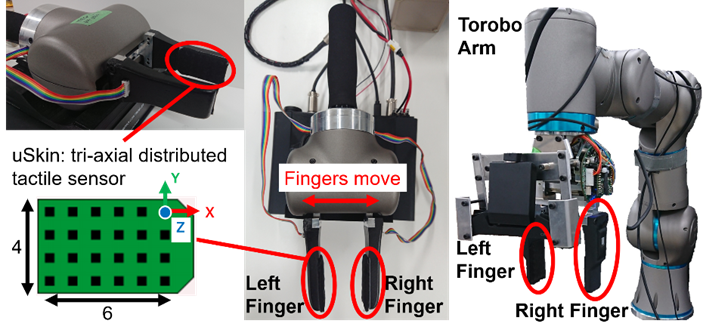
それでは、実際に触覚センサを使って物体を掴んでみましょう。すると、下図のように様々な物体との接触状態が見て取れます。強く掴むほど青い丸が大きくなり(Z軸方向)、左右(X軸方向)や上下(Y軸方向)に引っ張ると青い丸もその方向に移動していることが分かると思います。このように、uSkinは物体との接触状態を分かりやすく提示してくれるセンサとなっています。
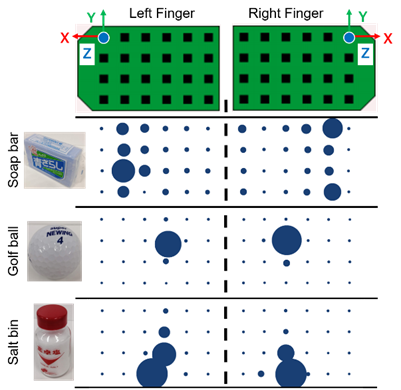
図から、硬い物体を掴んだ時は物体の表面の形に合わせて触覚センサが反応していることが分かります。例えば、石鹸が触覚センサに触れる面は四角く広がっているように見えます。また、ゴルフボールそのものは球の形をしているため、触覚センサに触れると、点のような触れ方をしているように見えます。さらに塩の瓶は底が大きくなっている形状なので、触覚センサ上では三角形のように見えます。これらの物体を強く掴むほど、触覚センサ上にその物体の接触面の形が反映されるようになります。
これが、マヨネーズのような柔らかい物体ならどうでしょうか。緩く掴んでいる時は、触覚センサと触れている面が長方形のように見えます(下図)。しかし、さらに強く掴んでいくと、力が加わっている部分が上下に分離した見た目になります。これは、強く掴んでマヨネーズが変形した結果、変形して張り出した部分が触覚センサの端に表れるようになったものと考えられます。
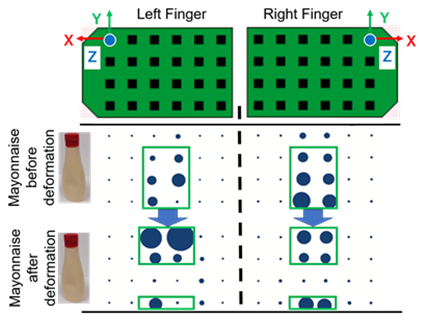
次に、物体を掴んだ後、持ち上げる時の様子を見てみます。下図は、物体を持ち上げている最中に滑りが生じた際の触覚センサの出力値になります。
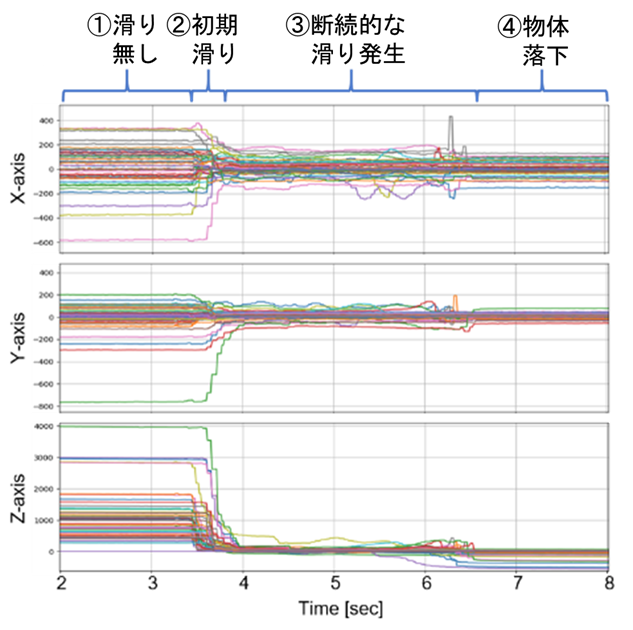
物体を掴んでから滑り落とすまでの様子が、グラフに表れています。初めは①触覚情報の波形が安定していますが、②初期滑りや部分滑りと呼ばれる状態が少しずつ発生します。ここでは目に見えて物体が滑っているわけではないですが、接触面を微視的に見ると、物体と触覚センサの相対変位がない領域と相対変位が生じる(つまり滑る)領域が混在し、前者の割合が減って後者の割合が増えていきます。その後、③接触面全体に渡って滑る領域のみになり、物体全体が目に見えて動く状態になります。グリッパから物体が抜け落ちるまで断続的に滑りが発生し、④抜け落ちて接触が無くなってしまっている様子が触覚センサ情報に表れているのが分かります。
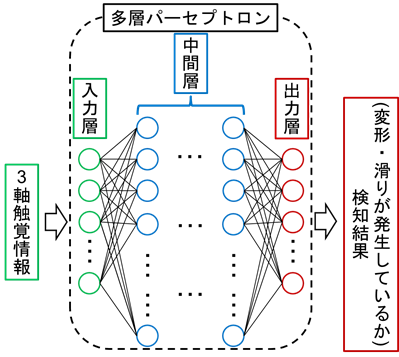
これらの状態を検知するために、今回は機械学習の手法の一つである多層パーセプトロンを用いました。いわゆるニューラルネットワークと呼ばれるものです。下図のように、多層パーセプトロンに触覚情報を与えて学習を行うことで、触覚情報に表れる物体の変形や滑りといった様々な現象を1つの検知器で処理することが可能になります。
この変形・滑りを検知するシステムを用いたグリッパによる物体把持の様子が以下の図になります。(a) 変形を検知するとグリッパが止まり、それ以上潰さないようになっています。(b) 滑りを検知すると、落とさないようにするためにより強く掴むようにグリッパが動きます。(c) ロボットアームを用いた場合でも同様に、変形・滑りを検知し、持ち上げることができています。こちらでは多層パーセプトロンの学習に使っていない未知の物体のピッキングを行いました。十分に変形や滑りの様子を学習することで、触覚情報だけでも未知の物体を潰さず・落とさず持ち上げることが可能になっています。

今回は変形と滑りの検知について説明しました。触覚を使った研究事例はここ数年で再び注目され始めており、ロボット系の国際会議で多く取り上げられるようになりました。産業への触覚センサ導入にはまだ課題は多くありますが、少しずつ導入事例が増え、触覚センサならではの課題解決ができていくのではないかと思います。
それではまた。
[1] S. Cui, R. Wang, J. Wei, F. Li and S. Wang, “Grasp State Assessment of Deformable Objects Using Visual-Tactile Fusion Perception,” 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 2020, pp. 538-544.














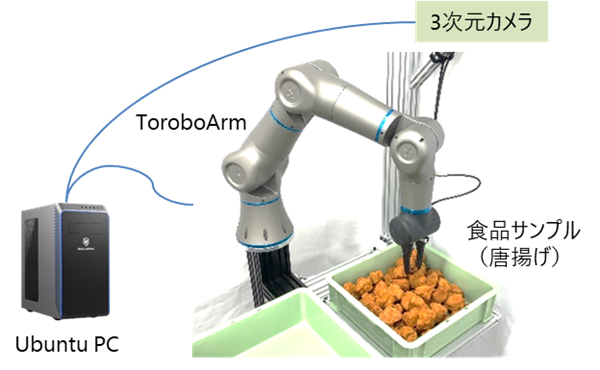


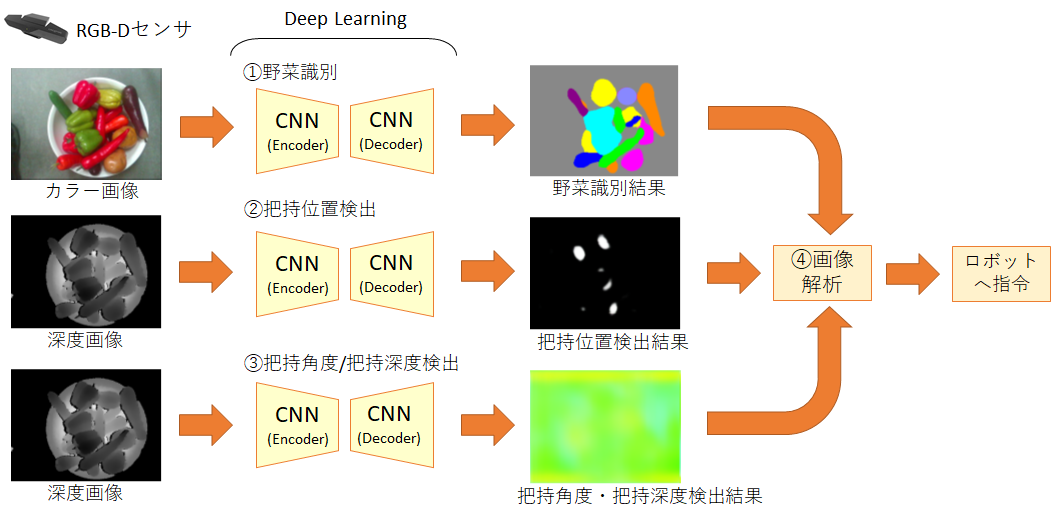
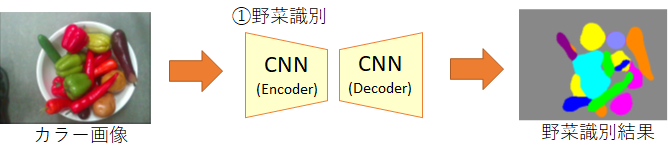
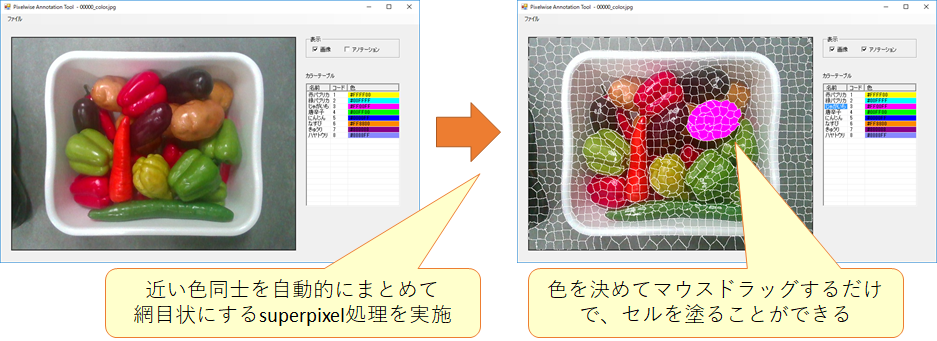
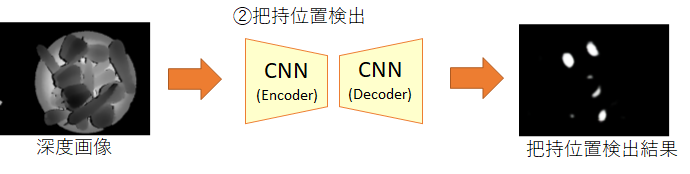

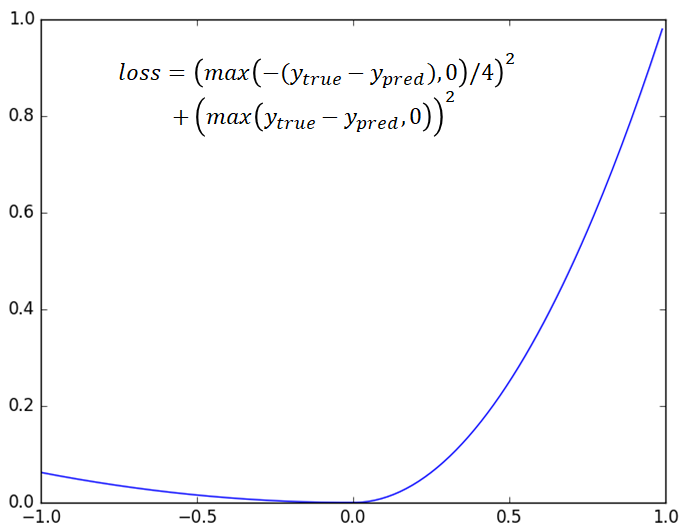
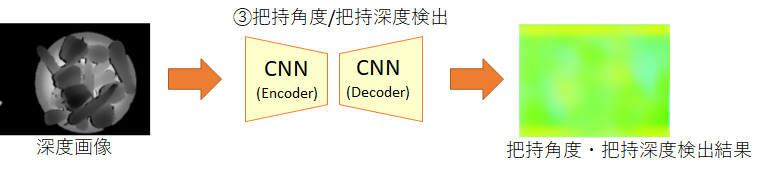
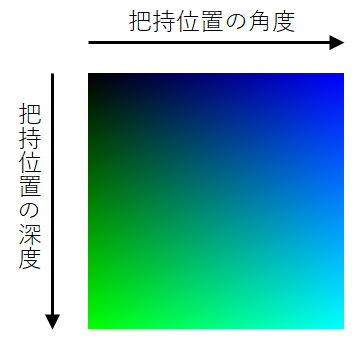

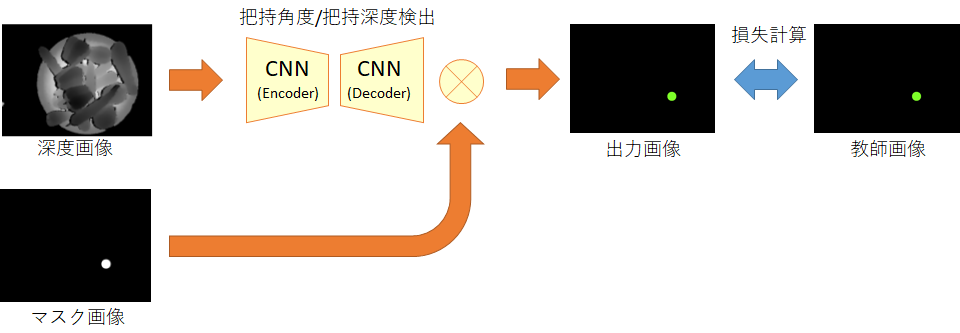

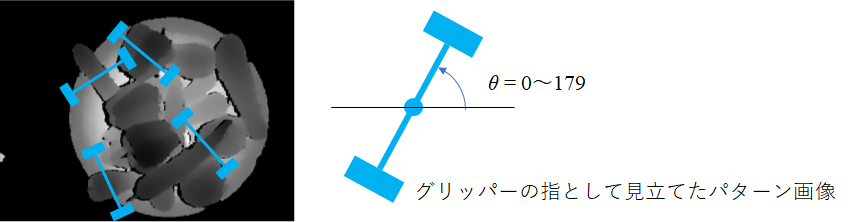
 深度画像に対してグリッパーのパターン(水色)を探索した結果
深度画像に対してグリッパーのパターン(水色)を探索した結果 [2] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla.”SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” arXiv preprint arXiv:1511.00561, 2015.
[2] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla.”SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” arXiv preprint arXiv:1511.00561, 2015.