
こんにちは、トロボです。
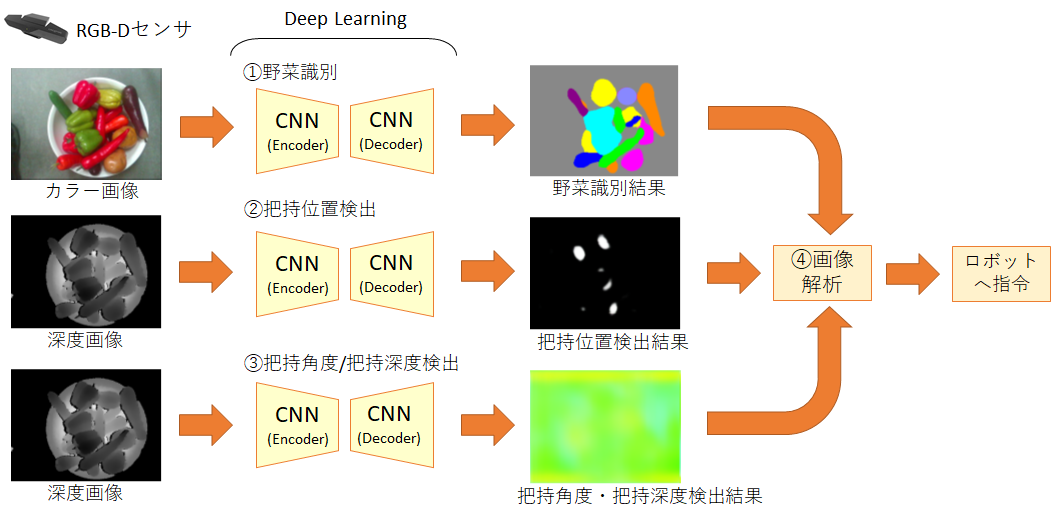
前回は『不定形物ピッキング』のデモの内容と、Deep Learning による認識の仕組みを紹介しました。そして、Deep Learning として ①野菜識別、②把持位置検出、③把持角度/把持深度検出 のためのEncoder-Decoder構造のCNNを使用していることを説明しました(下図)。
今回の記事では、これらのCNNのパラメータ(重み)の学習方法を紹介します。
①野菜識別用のCNNの学習方法
野菜識別用のCNNは、カラー画像を入力すると、各分類クラスの尤度を画素ごとに出力します。(なお、推論時には各画素で最も尤度の高いチャネル番号を出力するようにさらにArgMaxレイヤーを最終段に追加します。)
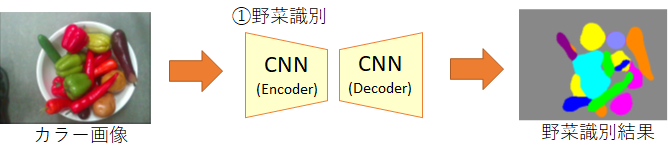
このような多クラス分類器としてのCNNにおいては、一般に出力画像と教師データとの差分を「交差エントロピー誤差」を損失として算出し、誤差逆伝搬させて学習します。(この手法の詳細に関しては多くの文献で解説されていますので、ここでは説明を割愛させて頂きます。)
ただ、この野菜識別のCNNの学習で最も大変な点は、教師データの作成の方です。一般的にはアノテーションツールを活用して、画素ごとに色分けした教師データ(上図の右)を作成します。
世の中のアノテーションツールを探したところ、効率的にアノテーション可能なツールは見つかりませんでした。というのも、世の中のほとんどのアノテーションツールは、マウスでクリックして閉多角形の頂点を描画し、その内部を指定色で塗るというものだったからです。閉多角形をきれいに作るには時間と神経を消耗します。そこで、弊社では独自の効率的なアノテーションツールを開発しました(下図)。
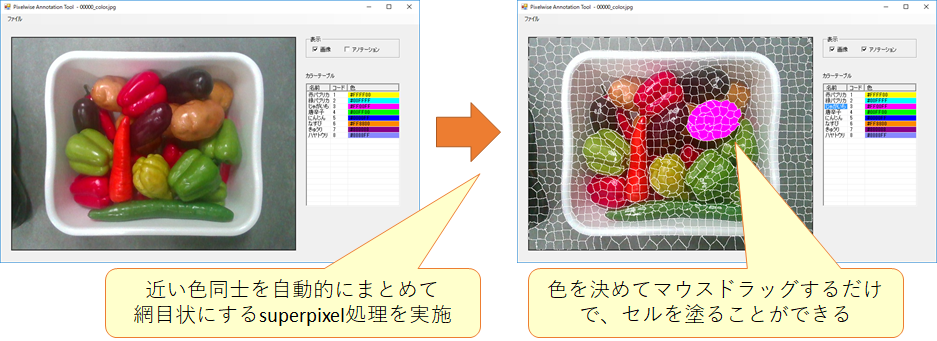
この独自のアノテーションツールは、カラー画像を読み込むと、色と位置が近い画素同士をセルまとめて網目状にするスーパーセル処理を行います。作業者は、塗りたい色を右側のテーブルから選び、マウスの左ボタンを押しながら対象のスーパーセルにマウスカーソルを当てるだけです。マウスカーソルに1度でも触れたセルは色が塗られるため、とても簡単かつ効率的です。また、複雑な形状の野菜も精確に塗ることができます。これにより、1つのカラー画像につき1分ほどで教師データを作成することができるようになりました。
②把持位置検出用のCNNの学習方法
把持位置検出用のCNNは、深度画像を入力すると、把持成功度の値(0.0~1.0)を画素ごとに出力します。そのため、このCNNはPixel-wiseの回帰問題として学習させます。
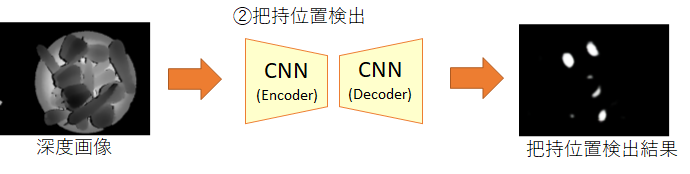
教師データは、把持位置(=グリッパーの中心位置)に白い丸(=1.0)を1つ描画した画像として作成しました(下図の中央)。

ロボットアームで毎回試行すると時間がかかってしまうため、今回は深度画像から目視で把持位置を判定し、教師データを作成しました。このような教師データを多数作成しました。そして回帰問題を解くため、教師データとの差分を最小二乗誤差として算出し、誤差逆伝搬法を用いてCNNを学習させました。
ただし、この方法では上手くいきませんでした。その原因は黒画素の扱いにありました。教師データの白画素(=1.0)は「把持可能な位置」を意味しますが、黒画素(=0.0)は「把持不可能な位置」を意味する訳ではありません。正しくは黒画素は、把持可能か把持不可能か不明な画素を意味します。すなわち、教師データの黒い領域には、白い領域となるべき箇所が残っている可能性があるということです(上図の右の「理想的な出力データ」)。しかし、本来ロボットアームで把持を試行できるのは1か所しかありません(一度試行すると、野菜の位置関係が変化します)。そのため、複数の把持位置を白く塗った教師データを作るのは好ましくありません。
そのための工夫として、最小二乗法を損失関数に使用するのはやめて、下図のようなグラフの関数を損失関数として採用しました。この損失関数を使うと、教師データが白い画素の場合は誤差の重みが大きくなり、教師データが黒い画素の場合は誤差の重みが小さくなります。
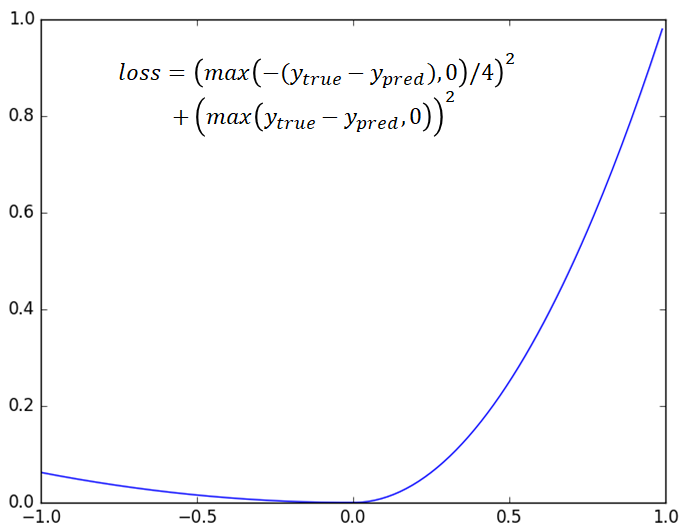
これにより、CNNは黒い画素よりも白い画素を優先的に学習するようになり、推論時には複数の白い領域を出力することができるようになりました(上図の右の「理想的な出力データ」がそれです)。
③把持角度・把持深度検出用のCNNの学習方法
把持角度・把持深度検出用のCNNは、深度画像を入力すると、把持角度(0~179)と把持深度(0~255)の2つの値を画素ごとに出力します。そのため、このCNNもPixel-wiseの回帰問題として学習させます。
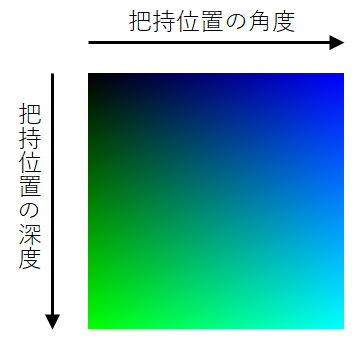
各画素が出力する2つの値は、色で表現すると下図のようになります。
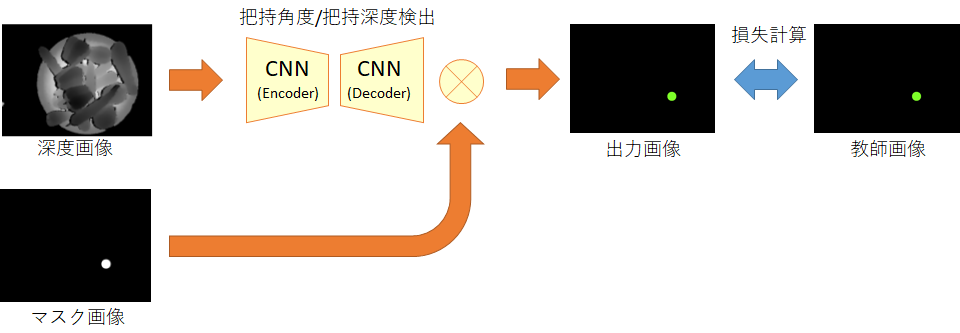
教師データは、把持角度と把持深度に応じた色で丸を描画した画像として作成しました(下図)。もちろん、この丸の位置は把持した位置です。

この教師データを用いて学習する際、注意しなければならないのは、「丸を描画した画素以外は学習で使用してはならない」ということです。というのも、黒い画素を学習に使用してしまうと「把持角度=0度、かつ把持深度=0mm」という誤った意味で学習してしまうためです。(②の把持位置のCNNの学習で黒い画素を学習に使用することができたのは、黒が誤った意味を持っていなかったためです。)
丸を描画した画素以外は学習に含めないように、教師データごとにマスクデータを用意しました、そして、学習時にはCNNの出力レイヤーにマスクデータを掛け合わせることで、マスクデータが黒(=0)の画素は損失が0となるようにしました(下図)。
これにより、正しい学習を行うことができました。
以上により、「ロボット × Deep Learning」の一例としての『不定形物ピッキング』のデモを実現することができました。
デモの動画を再掲します。
弊社は、このデモのような「ロボット × Deep Learning」の研究領域に、ロボットを開発・供給して貢献したいと考えています。(弊社が今回のデモで実装した Deep Learning はあくまで一例です。) この記事の内容が、皆さんの Deep Learning の研究のご参考になりましたら幸いです。
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something.
I think that you can do with some pics to drive the message
home a bit, but instead of that, this is magnificent blog.
A great read. I will definitely be back.
If some one wishes to be updated with most up-to-date technologies after that he must
be visit this web site and be up to date all the time.