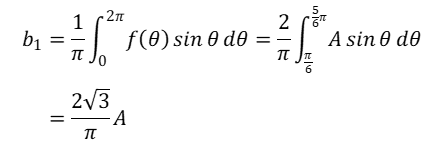こんにちは。トロボです。
今回の記事では前回に引き続きブラシレスモータについてお話させて頂きます。
前回の記事ではブラシレスモータのトルク定数についてお話ししました。モータ定数の中でもトルク定数は機械的な出力に直結する重要なパラメータですが、トルク定数と対となる定数として逆起電力定数があります。ブラシ付き直流モータにおいてはトルク定数と逆起電力定数は等しくなると言われていますが、ブラシレスモータではどうなるでしょうか。原理的には逆起電力定数とトルク定数は等しくなりますが、やはり測定方法や電流・電圧の定義によって違いが生じることがあります。
本記事ではブラシレスモータの逆起電力定数に焦点を当ててお話をしようと思います。
逆起電力の測定方法
一定速度で回転するブラシレスモータの逆起電圧波形は一般に正弦波となることから、逆起電力の測定にはいくつか方法があります。
◆ 電圧波形の振幅
もっとも単純なのは、オシロスコープでモータ端子間の電圧波形を観測し、その振幅を求めるという方法です。線間電圧の測定となるため、測定器のグランドとのショートに注意が必要になります。
◆ 整流波の平均値
オシロスコープを使わない測定として、三相交流を全波整流しその平均値を直流電圧計で測定する方法があります。
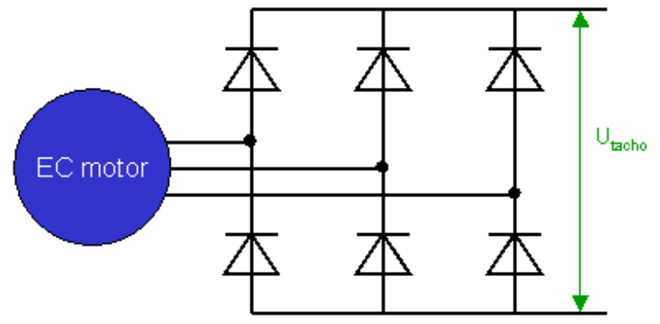
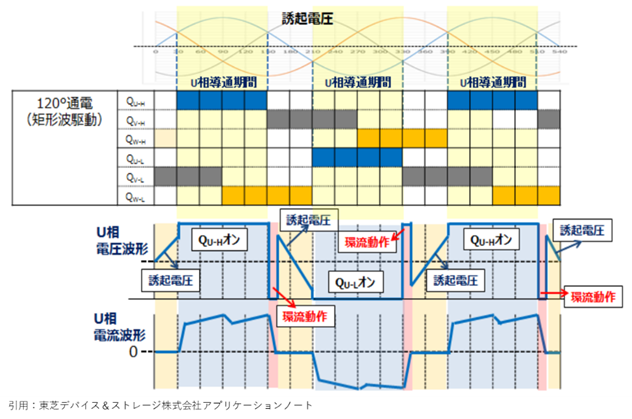
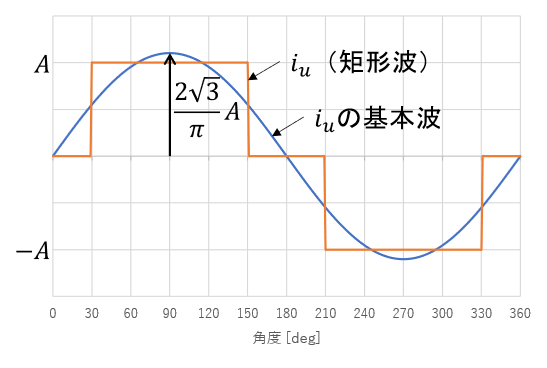
測定回路はモータドライバのインバータをそのまま利用できます。すべてのアームのスイッチをオフにすることで、スイッチング素子のボディダイオードで全波整流回路が構成されます。逆起電力の全波整流波の平均値はDCリンク部に現れます。三相交流の全波整流波をまとめたグラフは下の図のようになります。
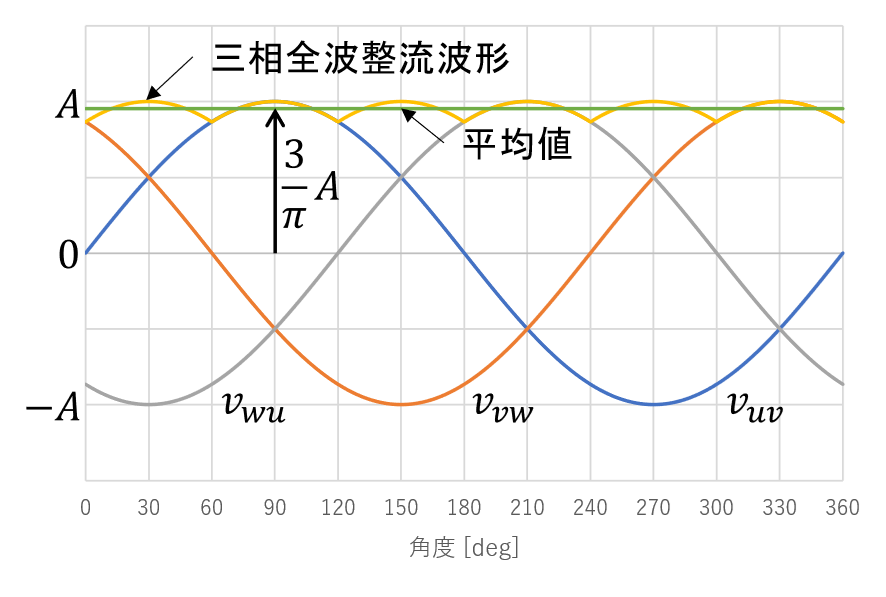
線間電圧振幅Aの三相交流を全波整流した波形は図中の黄色の線であり、次のように定式化できます。
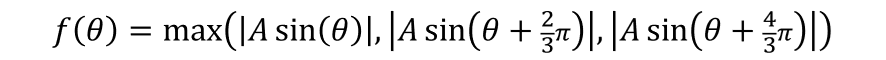
この波形の一周期分の平均値を計算します。
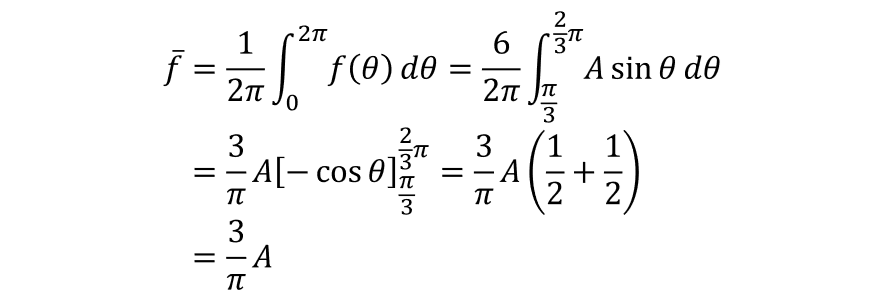
以上より、三相全波整流波の平均値は図中の緑の線のように線間電圧の振幅の3/π倍になります。
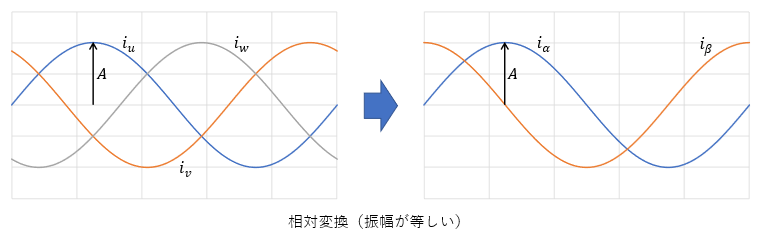
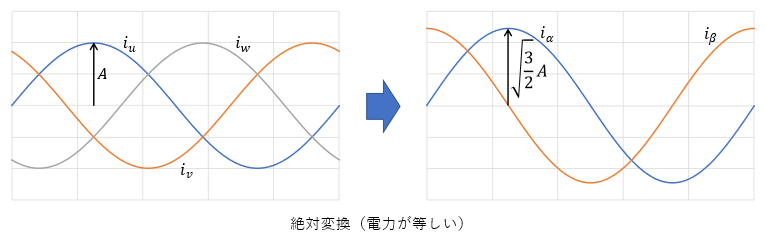
測定した電圧値を回転数で割れば逆起電力定数が求まることになります。しかし上記二つの方法は電圧値が線間電圧を使った測定であり、ブラシレスモータをベクトル制御するときのq軸電圧とd軸電圧はスター結線電源の相電圧を変換した電圧です。したがって、ベクトル制御の逆起電力定数を求めるときには、電圧値を相電圧相当に変換してから回転数(rad/s)で割る必要があります。線間電圧の振幅を相電圧の振幅に変換するときには、√3で割ります。また、正弦波駆動では相対変換と絶対変換の変換手法があるので、絶対変換のときには相電圧振幅の√(3⁄2)倍が電圧値になります。
以上より、全波整流で測定した逆起電力定数を正弦波駆動の相対変換と絶対変換に換算するときには以下の表の係数をかければ求まります。

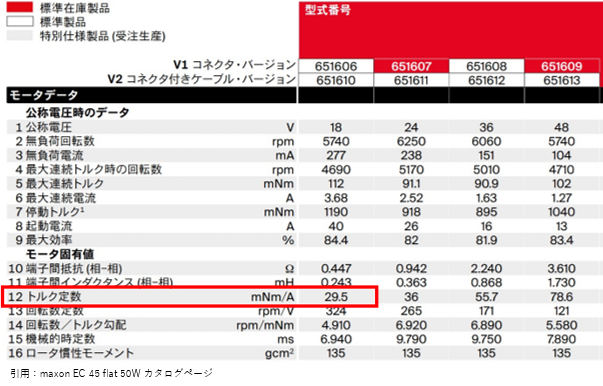
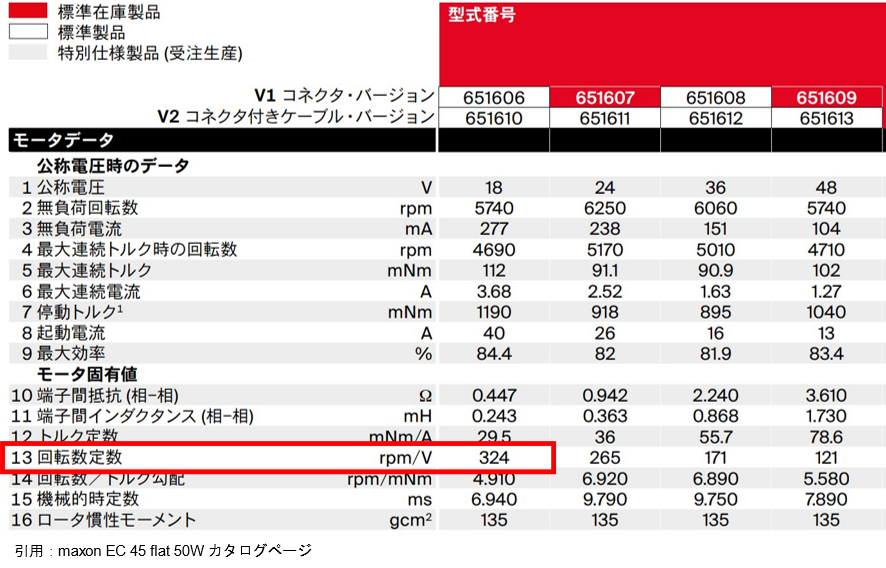
トルク定数のときと同様、モータのスペックシートをもとに、逆起電力定数を換算してみましょう。今回もmaxon EC 45 flat 50Wの18Vタイプを例に逆起電力定数を換算してみます。maxon EC motorの逆起電力定数は全波整流で測定されているため、正弦波駆動で使用する時には換算が必要になります。スペック表を確認すると、回転数定数は324 rpm/Vとなっています。まずはこれを逆起電力定数の次元に変換すると、29.5 mV/(rad/s)になります。これを相対変換の正弦波駆動に換算すると17.8 mV/(rad/s)、絶対変換の正弦波駆動に換算すると、21.8 mV/(rad/s)となります。
トルク定数と同様に総じて、矩形波駆動よりも正弦波駆動の逆起電力定数が小さくなるという点に注意が必要です。
逆起電力定数とトルク定数の関係
前回の記事で正弦波駆動の絶対変換では変換前後で電力が同じになると書きましたが、電力が同じならば機械出力についても変換前後で同じになります。このことから、絶対変換ではトルク定数と逆起電力定数が等しくなります。また、前回のトルク定数の換算表と逆起電力定数の換算表を見比べると、絶対変換のときの変換係数が同じになっています。よって、矩形波駆動でのトルク定数と全波整流で測定した逆起電力定数も等しくなることがわかります。トルク定数と逆起電力定数の関係をまとめると以下の表のようになります。

先ほどのmaxon EC motorの例で回転数定数を逆起電力定数に変換すると、スペックシートのトルク定数に等しくなっていたのは以上のことが理由になります。
相対変換のときだけ、トルク定数は逆起電力定数の1.5倍になることにも注意が必要です。
ただし、正弦波駆動の絶対変換で逆起電力定数とトルク定数が等しくなるのは、モータの鎖交磁束と逆起電力が歪みのない正弦波で、電流が理想的に制御されている場合のみです。実際のモータは逆起電力が若干台形のような波形になっていることもあり、完全な電流制御を行うのも困難なので等しくならないことも多いです。
以上、ブラシレスモータの逆起電力定数についてのお話でした。
矩形波制御でトルク定数と逆起電力定数が一致していても、正弦波駆動では係数がかかり、相対変換ではトルク定数と逆起電力定数が一致しないことに注意していただければと思います。