
こんにちは、トロボです。
昨年末の国際ロボット展(iREX2017, 会期2017/11/29~12/2)にて、弊社では不定形物ピッキングのデモを行いました。この不定形物ピッキングのデモの内容を紹介します。
下の写真は弊社ブース全体の様子です。左側で不定形物ピッキングのデモを動かしました。

不定形物ピッキングのデモの概要を簡単に説明いたします。
不定形物ピッキングのデモの内容
デモの全体像を下図に示します。
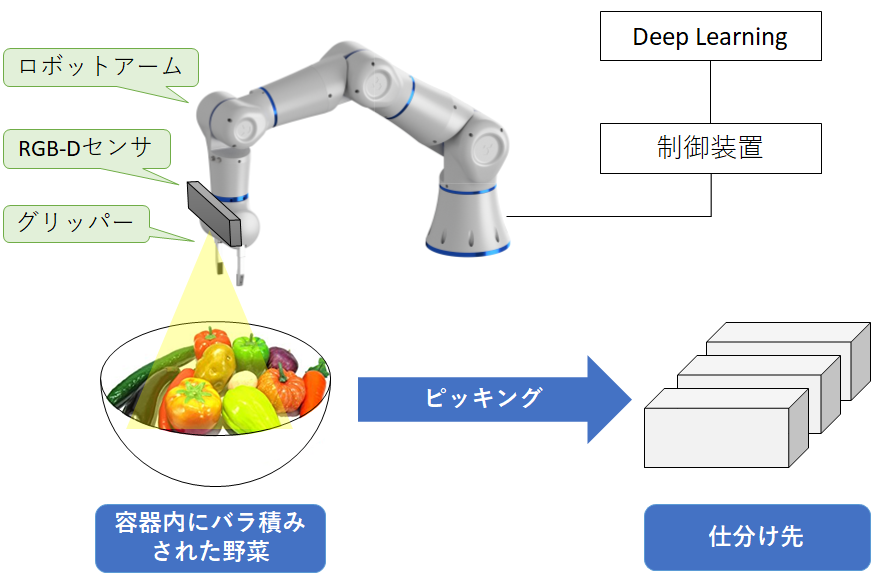
容器内に多数の野菜がバラ積みされており、ロボットアームと2本指グリッパーを使ってピッキングし、野菜の種類に応じてカゴに仕分けます。ロボットアームの先端にRGB-Dセンサ(Intel社製のRealSense SR300)を取り付けてあり、このセンサで容器の上方からカラー画像と深度画像を取得します。Deep Learning を用いてカラー画像と深度画像からから野菜の認識と把持位置を検出を行います。そして制御装置がロボットアームを動作させて野菜をピッキングし、野菜の種類に応じたカゴに仕分けます。
デモのビデオをご覧頂ければと思います。
デモの様子はいかがでしたでしょうか。このシステムを使用することで、バラ積みされた不定形物の野菜を自動的に仕分けることができます。
本デモを展示した目的
弊社では、「ロボット × Deep Learning」という組み合わせが今後の産業に一層貢献をもたらすと考えています。今回のデモは、このような「ロボット× Deep Learning」による一例をお見せすることが目的です。
従来のピッキングでは、テンプレートマッチングをベースとしたアルゴリズムが把持位置の検出に採用されてきました。例えば、従来ではボルトの深度画像(下図)に対してグリッパーのパターン(水色)を探索することで、把持可能な位置を検出するといったアプローチがなされてきました。
 深度画像に対してグリッパーのパターン(水色)を探索した結果
深度画像に対してグリッパーのパターン(水色)を探索した結果[1] Y.Domae, H.Okuda, et.al. “Fast Graspability Evaluation on a Single Depth Maps for Bin-picking with General Grippers”, ICRA2014.
しかし、このテンプレートマッチングをベースとした把持検出は、野菜のような不定形物の画像に対しては苦手です。その理由は、野菜は同じ種類であっても千差万別の形状をしており、『想定外』の形状によってマッチングにミスが生じてしまうからです。
そこで、Deep Learning の出番です。Deep Learning を使うことで、テンプレートよりも柔軟な特徴量を見つけ出し、より高精度で把持位置を検出することが可能となります。
さらに、Deep Learning は高解像度・高密度なデータではなくても粗いデータから答えを類推できるという特性があります。そのため、高価なセンサや複雑な画像処理が不要になる場合があります。
Deep Learning による認識の仕組み
今回採用した Deep Learning による認識の仕組みを紹介します。RGB-Dセンサからカラー画像と深度画像を取得した後、下図に示すようなEncoder-Decoder構造のCNN (Convolutional Neural Network) に入力します。Encoder層で次元を圧縮することで重要な特徴量だけを抽出し、Decoder層でタスクに合わせた画像データを生成することができます。このCNNはSegNet[2]を参考に実装しました。
 [2] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla.”SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” arXiv preprint arXiv:1511.00561, 2015.
[2] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla.”SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” arXiv preprint arXiv:1511.00561, 2015.
デモのシステムの全体フローは下図のようになります。
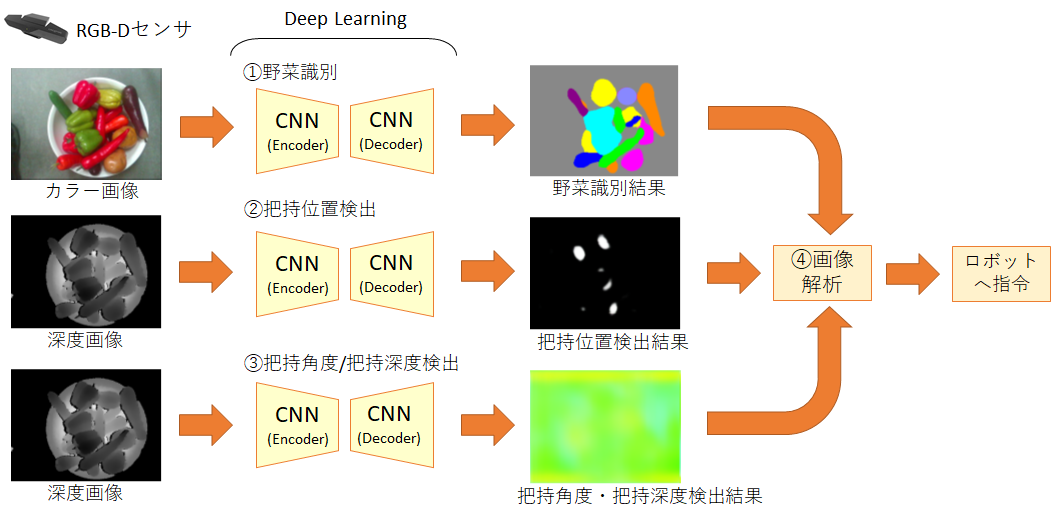
RGB-Dセンサからカラー画像と深度画像を取得した後、Encoder-Decoder構造のCNN を使用して野菜種別・把持位置・把持角度深度を表す画像を出力します。そしてそれらの画像を解析することで、野菜の種別と把持位置を決定することができます。
それでは、各CNNが出力する画像データについて紹介します。
①野菜識別のCNN
このCNNは、RGB-Dセンサから取得したカラー画像が入力されると、画素ごとに野菜の種類ごとの尤度(likelihood)を出力します。すなわち、画素ごとに多クラス分類問題を解くCNNとなっています。下図の出力画像は、画素ごとに最も尤度の高い野菜を、野菜に対応した色で描画したものです。
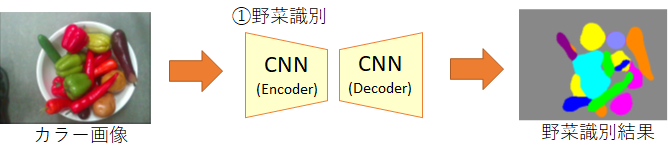
今回のデモに使用した野菜は以下の8種類です。似た色の野菜は学習がうまくいかないこともありました。

各野菜のコード値に対する色分けを下図に示します。色分けはあくまで人が見てわかりやすくするためのものです。

②把持位置検出のCNN
このCNNは、RGB-Dセンサから取得した深度画像が入力されると、把持可能な位置(グリッパーの中心位置)を白、把持可能でない位置を黒として出力します。
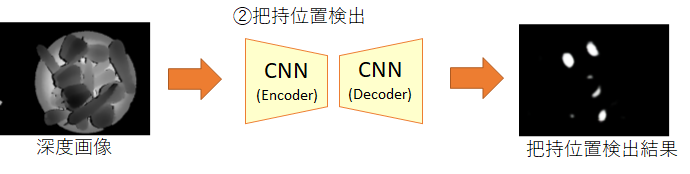
上図の出力画像の中で、白領域の面積が最も大きい箇所の中心座標を、最良の把持位置と決定します。
なお、グリッパーが野菜を把持する際は、UFOキャッチャーのように野菜の上方で水平面上の位置決めを行い、鉛直軌道で野菜を掴みにいくように動作させることとしています。そのため、鉛直上方から撮影した深度画像さえあれば、グリッパーが野菜を掴むことができる位置を、Deep Learning が判断することができます。(もし、グリッパーを鉛直軌道以外の複雑な軌道で動作させると、深度画像ではわからないオクルージョンの情報も Deep Learning に必要になってしまいます)
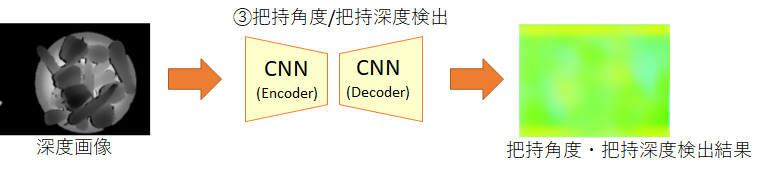
③把持角度・把持深度検出のCNN
このCNNは、RGB-Dセンサから取得した深度画像が入力されると、「把持の角度」と「把持の深度」を表すカラー画像を出力します。
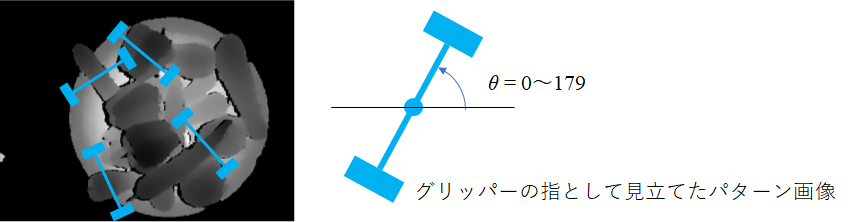
「把持の角度」とはグリッパーを鉛直上方から見た時の水平面上の回転角度のことで、値域は0~179となります(下図)。
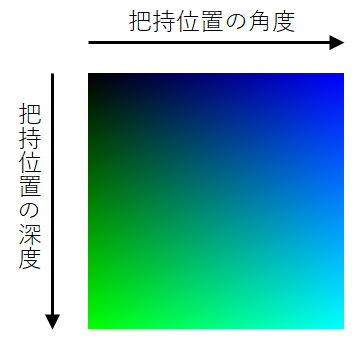
「把持位置の深度」とは、グリッパーで把持する位置の深度(単位はmm)です。
このCNNは、下図のように「把持位置の角度」を青色の強度で、「把持位置の深度」を緑色の強度で表現した画像を出力します。
④画像解析
①~③のCNNの出力画像を基に、最良の把持位置を決定し、それに対応する把持角度・把持深度・野菜種類を判定します。そしてその判定結果を基に制御装置でロボットアームを操作することにより、野菜をピッキングして仕分けることができます。
以上、「ロボット × Deep Learning」の一例として、不定形物ピッキングデモの内容を紹介しました。
次回は、このデモにおける各CNNの学習方法を紹介します。